Embodied social agents have recently advanced in generating synchronized speech and gestures. However, most interactive systems remain fundamentally reactive, responding only to current sensory inputs within a short temporal window. Proactive social behavior, in contrast, requires deliberation over accumulated context and intent inference, which conflicts with the strict latency budget of real-time interaction.
We present ProAct, a dual-system framework that reconciles this time-scale conflict by decoupling a low-latency Behavioral System for streaming multimodal interaction from a slower Cognitive System which performs long-horizon social reasoning and produces high-level proactive intentions. To translate deliberative intentions into continuous non-verbal behaviors without disrupting fluency, we introduce a streaming flow-matching model conditioned on intentions via ControlNet. This mechanism supports asynchronous intention injection, enabling seamless transitions between reactive and proactive gestures within a single motion stream. The system is deployed on a physical humanoid robot.
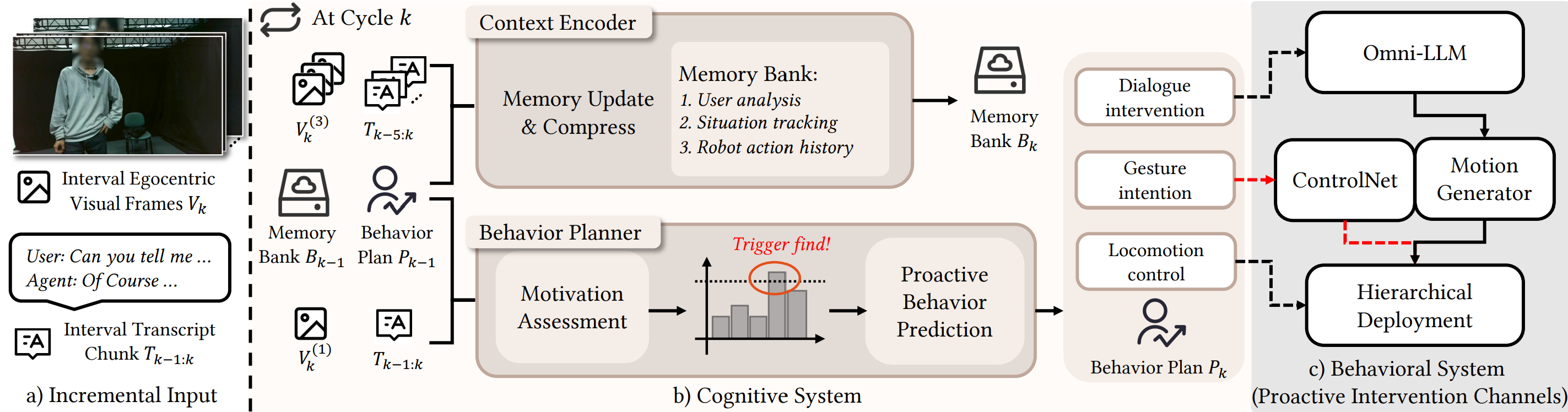
ProAct incorporates two systems to reconcile low-latency reactive control with longer-horizon deliberation: a fast Behavioral System for streaming multimodal interaction, and a Cognitive System for compressed-context reasoning and proactive planning.
The Behavioral System maintains the real-time interaction loop, producing streaming verbal and non-verbal responses through a cascaded architecture that connects a streaming omni-modal LLM with a streaming motion generator. The two channels operate asynchronously: verbal responses follow a turn-based pattern, while motion generation runs continuously to maintain embodied presence throughout the interaction.
The Cognitive System provides slower, LLM-driven deliberative reasoning of the context in parallel with real-time interaction: it compresses accumulated history via a Context Encoder into a bounded memory and uses a Behavior Planner to assess motivation and plan actions. These components run continuous reasoning
cycles within a fixed time budget to keep inference timely and consistent.
We introduce a real-time motion synthesis framework that utilizes Conditional Flow Matching (CFM) to transform Gaussian noise into motion via a learned velocity field. This approach employs an optimal-transport path and a transformer-based backbone to model dyadic interactions, processing synchronized audio streams to generate both expressive speaker gestures and attentive listener behaviors. To ensure temporal continuity during streaming, an overlap-and-cache scheme is implemented, effectively eliminating boundary discontinuities between windows.
To incorporate high-level semantic intentions without degrading rhythmic synchronization, the model integrates a disentangled ControlNet architecture that decouples text-based control from the frozen, audio-driven base generator. This unified system enables seamless transitions between reactive and proactive behaviors while maintaining a generation speed faster than real-time playback.
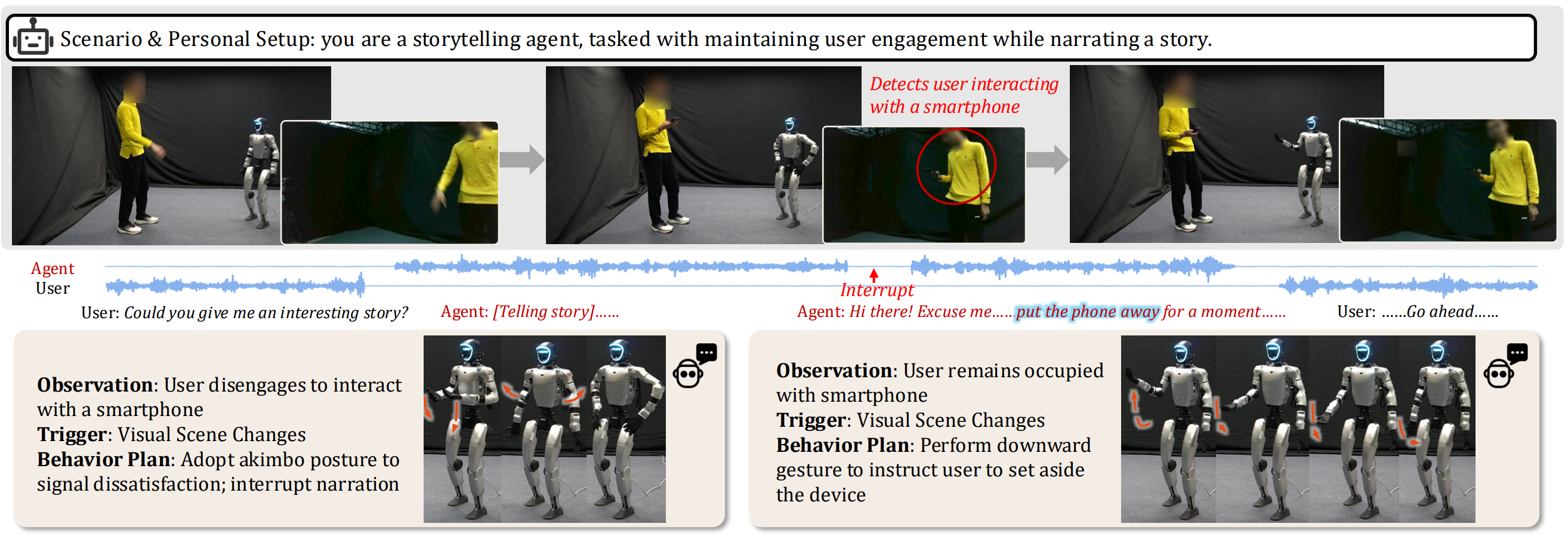
Demonstrations of ProAct intermediate outputs on the specific tasks are shown below to illustrate how the system generates proactive behaviors through the dual-system architecture. Case 3 further compares the system with the one without the Cognitive System to highlight the effectiveness of the dual-system design in generating timely and context-aware proactive behaviors.